
缓存是后端程序员永远绕不开的一个话题,今天在做一个需求的时候,偶然的发现我们的数据库代理服务有200w+的qps,对于to B的业务来说这已经很高了,所以想借此机会总结一下。
缓存更新策略
在使用缓存的时候,一个老大难的问题就是怎么保持缓存和db的数据的一致性。这就涉及了缓存的更新策略下面的导图分别从数据更新、数据删除和异步更新这3个角度来对更新策略做归类。
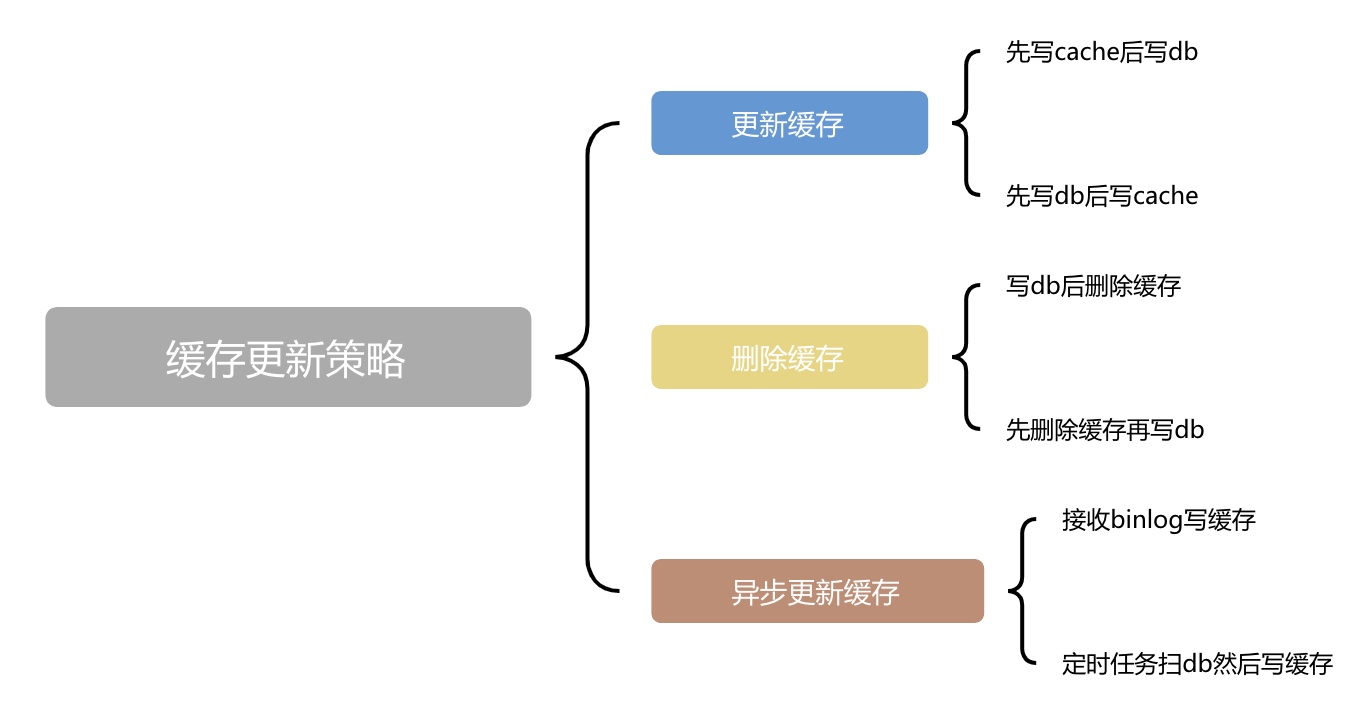 除了第3种异步更新缓存外,其他的情况都可以看作是友“2个动作”完成的。因此如果第1个动作成功了第2个动作失败了就会造成一些问题
除了第3种异步更新缓存外,其他的情况都可以看作是友“2个动作”完成的。因此如果第1个动作成功了第2个动作失败了就会造成一些问题
- 更新缓存成功但是更新db失败了,就造成了脏数据
- 更新db成功了但是更新缓存失败了,会读取到已经过期的数据
- 更新db成功了但是删除缓存失败了,流量低还好,如果瞬间有大量的请求获取这条新写入的数据那么就对db造成压力了
- 删除缓存成功但是更新db成功了,与上一条类似,没有了缓存的保护,可能瞬间对db造成压力
优化的方式
我的服务读取缓存的流程是:
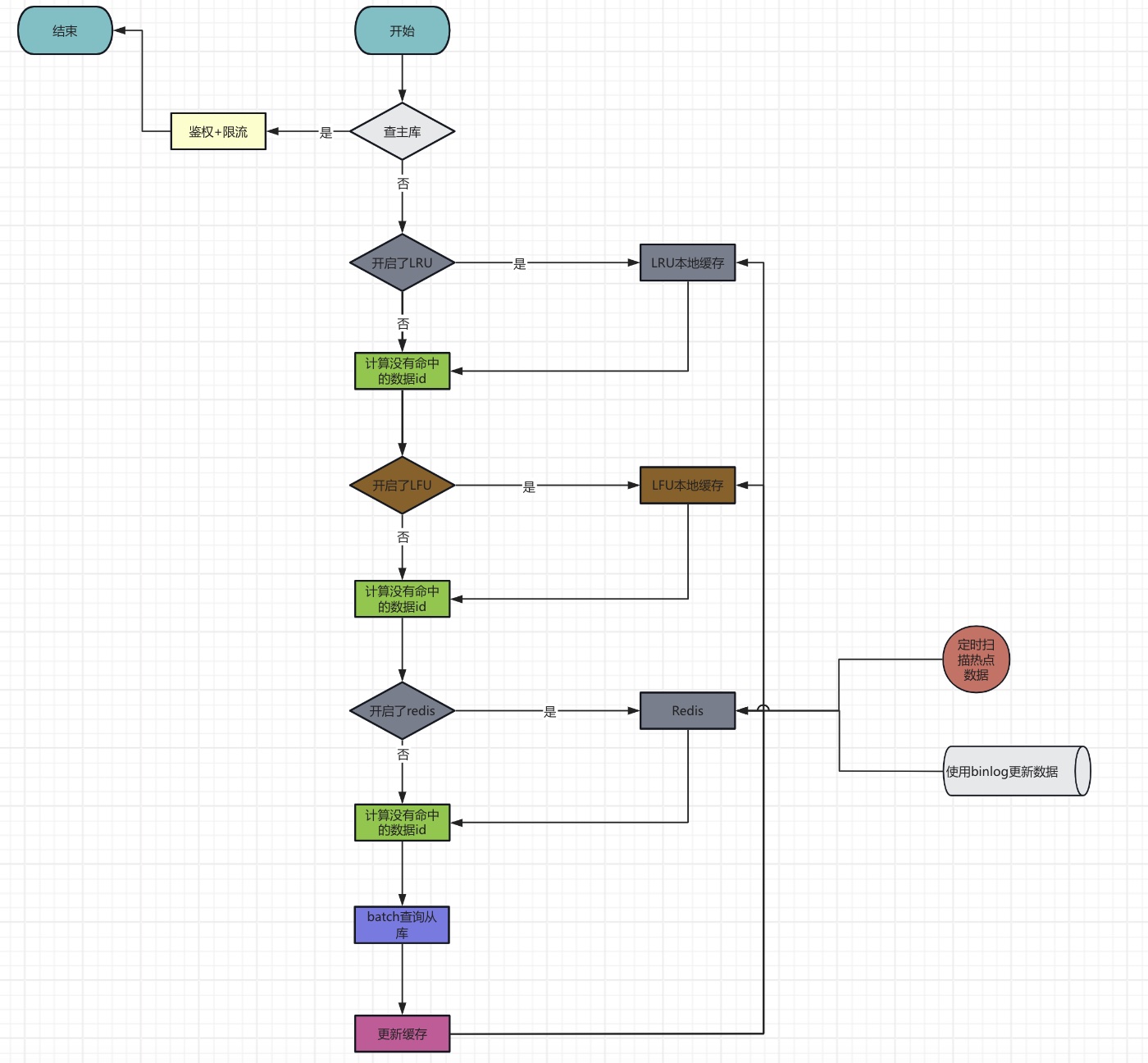 需要强调的是:
需要强调的是:
- 缓存分为本地缓存和
redis分布式缓存。本地缓存是由LRU和LFU组成,他们只是作为Redis不可用的时候的一个备用选项,平时是关闭的。因为是分布式系统,本地缓存很难通过“异步“更新,而是更多选择从db读出来以后更新。 - 查询数据库的时候是批量查询。
- 支持直接查主库,但是有严格的鉴权和限流机制
- 通过binlog和扫描热点数据来异步的更新Redis中的数据
- 即使查不到的数据也会写入到缓存,避免不存在的数据对数据库造成压力
本地缓存 vs 分布式缓存
那么有了分布式缓存后还需不需要本地缓存呢?先来分析一下他们的优劣势吧!
本地缓存
优势
- 读取速度快
- 生命周期与业务进程是一致的
劣势
- 在分布式系统中很难做到数据统一更新
- 在进程重启的时候数据会清空,此时缓存层完全是空的
分布式缓存
优势
- 可以容易地做到数据统一更新
- 进程重启后无需担心缓存失效问题
- 可以弹性扩充,不用受业务服务的束缚
劣势
- 读取速度赶不上本地缓存
- 在业务集群存在的情况下,缓存集群可能挂掉
所以它俩并不冲突,而是可以成为很好的互补。 也就是说本地缓存还是很有研究必要的,因此我撸了一下简易版的LRU和LFU的代码。
LRU
最近做少使用列表。 当插入一个元素的时候就把它插入到列表的指定位置,这个位置可以是最前面,也可以是指定的位置,这个由业务和业务的程序员决定。当列表的长度到达capacity的时候,就删除列表的尾部元素异腾出空间,整体的逻辑如下
type entry struct {
key, val string
}
type LRUCache struct {
capacity int
list *list.List
keyToElement map[string]*list.Element
}
func NewLRUCache(capacity int) LRUCache {
return LRUCache{
capacity: capacity,
list: list.New(),
keyToElement: make(map[string]*list.Element),
}
}
func (lru *LRUCache) Get(key string) (bool, string) {
if e, ok := lru.keyToElement[key]; ok {
lru.list.MoveToFront(e)
return true, e.Value.(entry).val
}
return false, ""
}
func (lru *LRUCache) Put(key string, value string) {
// 存在则更新
if e, ok := lru.keyToElement[key]; ok {
e.Value = entry{key: key, val: value}
lru.list.MoveToFront(e)
return
}
// 不存在则插入
lru.keyToElement[key] = lru.list.PushFront(entry{key: key, val: value})
if len(lru.keyToElement) > lru.capacity {
delete(lru.keyToElement, lru.list.Remove(lru.list.Back()).(entry).key)
}
}
LFU
LFU 是一种基于访问频率的缓存淘汰算法,适合访问模式稳定的场景,但对突发流量和历史数据敏感。每个元素都维护了一个访问频率,每一次读取和更新的时候,这个频率就会+1。当列表满了的时候,会删除访问频率最低的数据,具体逻辑如下
type entry struct {
key, val string
freq int
}
type LFUCache struct {
capacity int
minFreq int
keyToElement map[string]*list.Element
lists map[int]*list.List
}
func NewLFUCache(capacity int) LFUCache {
return LFUCache{
capacity: capacity,
keyToElement: make(map[string]*list.Element),
lists: make(map[int]*list.List),
}
}
func (lfu *LFUCache) pushFront(e *entry) {
if _, ok := lfu.lists[e.freq]; !ok {
lfu.lists[e.freq] = list.New()
}
lfu.keyToElement[e.key] = lfu.lists[e.freq].PushFront(e)
}
func (lfu *LFUCache) getEntry(key string) *entry {
node := lfu.keyToElement[key]
if node == nil {
return nil
}
e := node.Value.(*entry)
lfu.lists[e.freq].Remove(node)
if lfu.lists[e.freq].Len() == 0 {
delete(lfu.lists, e.freq)
if e.freq == lfu.minFreq {
lfu.minFreq++
}
}
e.freq++
lfu.pushFront(e)
return e
}
func (lfu *LFUCache) Get(key string) (bool, string) {
if v := lfu.getEntry(key); v != nil {
return true, v.val
}
return false, ""
}
func (lfu *LFUCache) Put(key string, value string) {
v := lfu.getEntry(key)
if v != nil {
v.val = value
return
}
if len(lfu.keyToElement) == lfu.capacity {
delete(lfu.keyToElement, lfu.lists[lfu.minFreq].Remove(lfu.lists[lfu.minFreq].Back()).(*entry).key)
if lfu.lists[lfu.minFreq].Len() == 0 {
delete(lfu.lists, lfu.minFreq)
}
}
e := &entry{key: key, val: value, freq: 1}
lfu.pushFront(e)
lfu.minFreq = 1
}