
raft也是分布式系统的一个共识算法,号称比paxos更容易理解。
状态机
raft中有一个状态机的概念。如果多个节点的初始状态相同,所经历的操作(日志中记录的command)以及这些操作的顺序一致,那么每个节点最终的状态是一致的。
节点的角色
raft协议里面的角色有三类
- leader 领导者
- follower 追随者
- candidate 候选者
每一个节点一开始都是follower, 每个folloewr都会一个随机的“超时时间”,一但超时时间到了之后follower没有接收到leader的心跳自己就会变成candidate,然后发起一轮竞选,如果能收到大多数的票数就是竞选成功称为leader。因此raft中哪个节点的随机超时时间短,最开始就哪个节点有可能成为leader。
leader的选举
- leader节点维护着自己与follower的心跳。一但follower在自己的超时时间内没有收到leader的心跳,就变成candidate并发起选举并投自己一票。
- 给其他节点发送vote rpc请求
- 等待结果,如果收到大多数的票数,那么自己就是leader,此时会给其他的节点发送rpc消息告诉他们“我是leader”;如果被告知别人当选就变成follower。如果票数被瓜分,那么等到超时时间过了以后再次发起选举。
当一个节点收到别人的选票的时候怎么判断是“投他还是投自己”?方法是比较term和entry log id。term可以理解为leader的任期,每个节点发起一轮选举的时候都会将自己的本地term_id自增,如果收到的投票的term比自己的小那么不会回复,如果比自己的大则投票给对方,如果一样就比较entry log id如果entry log id大就投票给对方否则不投。entry log id是该节点在该term下的最大的entry log id。
所以raft中因为随机超时时间的存在,极大地避免了同一时刻多个节点同时竞选的情形。能不能当leader取决于你现在的数据”够不够新“。
怎么确保只有一个leader
- 在一个选举周期里(一个term内),一个节点只能投一票。
- 获得大半数票的节点才能成为leader。
- 获得leader的节点的term以及entry log id不能落后于其他的节点。
- 每个结点的“超时时间”是随机的,可以认为每个节点都不相同,同时竞选的可能性比较小。
- 如果一个leader 的term比另一个节点的term小,那么会自动变成follower
数据的同步
和zk的zab协议一样,raft也是先在大多数的节点上写入entry log后,然后通知各个节点提交。但是在描述上二者有区别,raft第一阶段叫commit,第二阶段叫apply。log entry的示意图如下
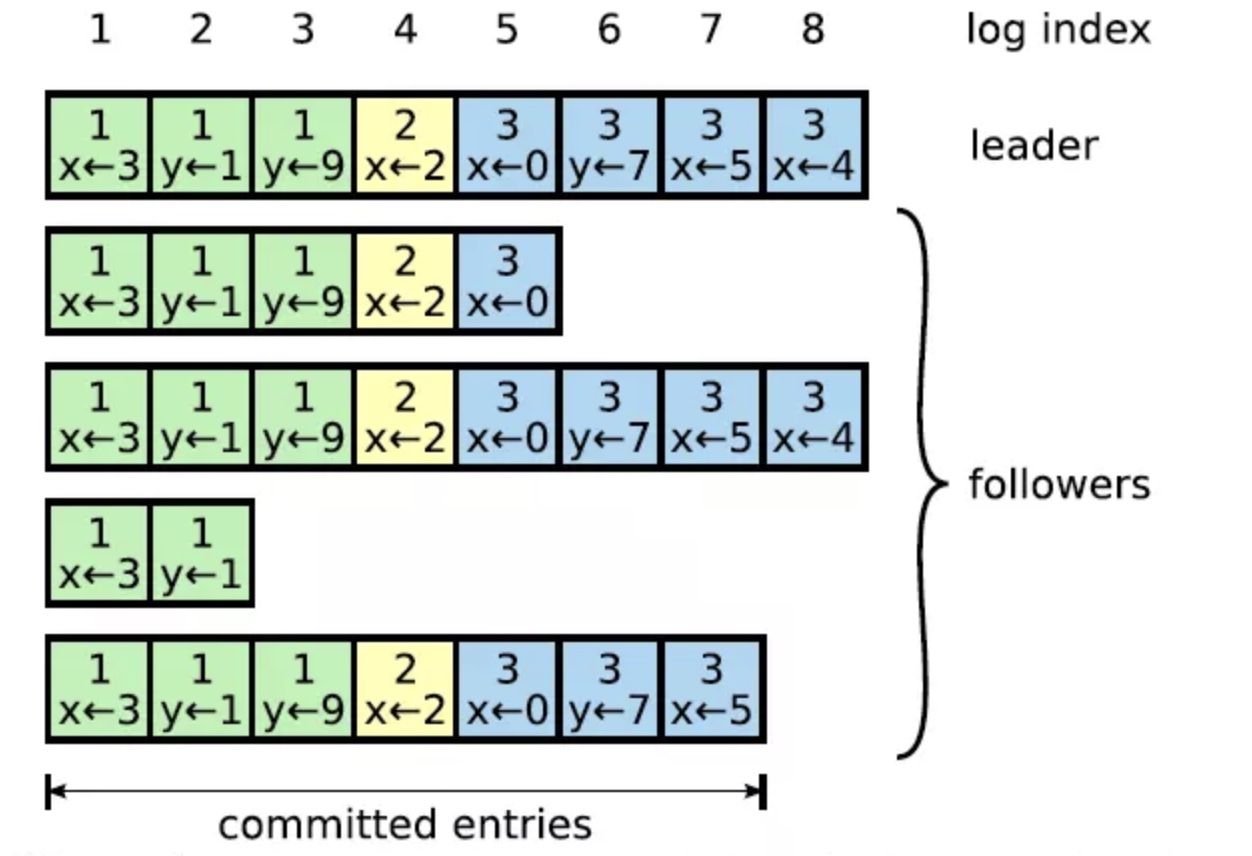
raft的每一个entry log都有一个entry log id,因此可以保证消息的顺序。
正常的同步
有了leader之后,集群的读写请求都要经过leader,follower只做备份。
当leader收到一个写请求后会记录一个entry log,然后把这个entry发送给集群中的follower,其他的follower收到entry之后会发送确认信息给leader,如果leader收到超过一半的follower的确认信息之后就会把数据写进去(前面记录entry并不会apply数据),并通知其他follower写数据。
任何一个follower重启后都会接收到leader的心跳,日志的内容也会与leader变成一致。
如果是leader挂了,那么肯定是team和team index最大的那个称为新的leader
重新选举leader后的数据同步
这个我想说的通俗点,就是leader与follower比较各自已经commit的entrty log id。直至找到二者的第一个”共同点“。之后leader就会把”共同点“后面的entrty log同步给follower。
下图是一个leader节点对应的follower的状态
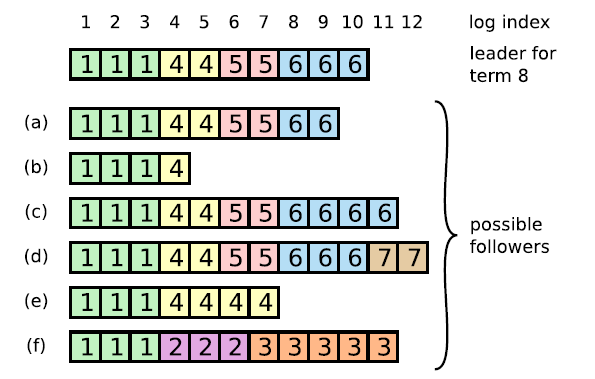
如果follower是b,那么leader与follower会先找到term为4 entrty log id为4的日志的位置作为”共同点“,之后leader会把”共同点“后面的日志同步给follower。
State Machine Safety
如果一个节点在某一个log entry的位置apply了这条log里面的command,那么其他节点也必须在这个log entry的位置apply这条log。