
ZooKeeper是一个分布式的,开放源码的分布式应用程序协调服务,是Google的Chubby一个开源的实现,是Hadoop和Hbase的重要组件。它是一个为分布式应用提供一致性服务的软件,提供的功能包括:配置维护、域名服务、分布式同步、组服务等。
zookeeper所能提供的功能
命名服务
在zk下创建一个节点作为服务,然后节点下面的子节点中存放该服务的各个机器的ip
配置管理
在zk下存放一个节点,当节点的数据发生变化的时候通知watch这个节点的client
集群管理
当一个服务的集群增加或者减少机器的时候会在相应的服务节点上增加或删除子节点并通知watch这个服务节点的的所有的client。如果子节点是顺序节点,那么可以顺理成章的把编号最小的那个作为master
选举算法
所有的节点都向zk的一个路径下面创建临时有序节点,序号最小的那个就是leader。
锁定和同步
保持独占:各个client在zk上创建一个相同的znode,创建成功的client就相当于获取到了锁。保持独占这个方法实现比较简单,但是zk是leader负责写入的,如果很多个客户端同时写的话会有问题。 控制时序:各个client往一个znode下面创建临时有序节点,创建的节点的编号最小的client获取到了锁。没获取到锁的client开始watch这个znode下面的节点。获取到锁的client执行完后删除这个锁节点,其他watch的client会受到通知然后看谁的编号最小谁就获取到了这个锁
获取锁的时候,创建的节点都是暂时的,如果获得锁的进程意外退出,那么这个暂时的节点会立马被删除。
高度可靠地数据注册表
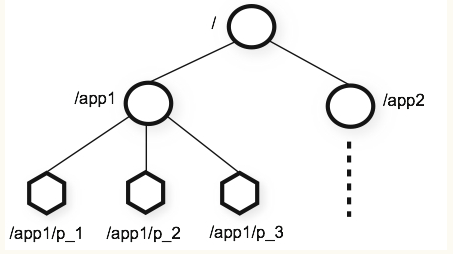
znode
ZooKeeper命名空间内部拥有一个树状的内存模型,其中各节点被称为znode。每个znode包含一个路径和与之相关的元数据,以及该znode下关联的子节点列表。
znode节点类型
- 持久节点
- 持久顺序节点
- 临时节点
- 临时顺序节点
znode可以存储一些数据外还有一些元数据
- czxid 创建节点的事务id
- ctime 创建时间
- mzxid 最后一次更新节点的事务id
- mtime 最后一次更新时间
- dataLength 数据长度
- numChildren 子节点数
会话
一个客户端与zookeeper连接后就形成了一个会话,客户端通过心跳与zookeeper保持联系。一单在超时时间内zookeeper没有收到心跳,就认为客户端已经“失联”,该客户端创建的所有临时znode都会被删除。
监视
客户端在读取特定的znode时可以设置监视这个znode,一单这个znode发生白变化客户端就会收到通知。
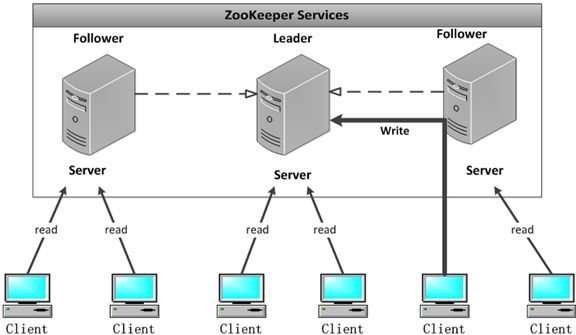
节点的角色
- leader
- follower
- observer
这3中角色的节点都能接受客户端的连接,都能响应读请求。如果follower或者observer收到了写请求会把这个请求转发给leader。
observer节点不会参与leader的选举。
为什么有observer?如果连接的客户端很多,那么就要扩充zk的节点数量。扩充了之后在选举的时候就会”变慢“,因此引入observer,扩充了节点数量但是参与投票的节点还没有那么多。
节点的状态
- leading 该节点目前是leader
- following 该节点目前是follower
- looking 该节点找不到leader,正在“寻找”leader
- observering 该节点是observer
选举
选举出现在三种情况
- 集群启动的时候。
- leader出问题了,需要重新选举。
- zxid的高位或者低位用尽。
在选取leader的过程中zookeeper集群是不可用的。 leaer通过心跳与follower和observer通信。当follower失去与leader的联系后会进入looking状态并“投自己一票”然后向集群内的其他节点广播。
选举的核心逻辑就是比较。比较什么呢?比较logicClock、zxid和serverid。
- logicClock是投票的轮数,每个节点发起投票的时候会将自己的logicClock加1。如果一个节点收到其他节点的投票的时候发现对方的logicClock比自己的小那么会直接忽略该投票。如果发现比自己的大,那么会更新自己的logicClock并重新广播自己的投票(自己的投票之前可能已经被别的节点忽略了)。如果logicClock一样大就去比较zxid。
- zxid是一个64位的数字,类似于事务id。前32位是epoch,有点类似于raft中的term, 每一次新leader的产生都会使前32位加1。后32位是此次“epoch”周期内的单调递增id。如果zxid一样就去比较serverid。
- serverid是集群内每个机器的id,一个zk集群在启动的时候就已经确认好了这个集群有几个节点。每一个节点的配置文件里都有这个集群每一个节点的信息。
一但zxid的高位或者低位用尽则会重新强制重新选举。
每次选举的时候各个节点首先都是“先投自己一票”然后广播。每一个follower收到“其他节点的投票”的时候都会与自己刚刚投的票相比较(logicClock、zxid和server id),如果自己被pk下去了那么就更新自己本地的投票然后广播,如果不需要修改就什么都不做。
因为每一个节点的投票信息其他的节点都会通过广播收到,因此每一个节点都有当前整个集群中所有节点的投票信息。一但有一个节点获取到了大多数票那么投票就结束了。
如果一个节点新加入或者宕机后新加入,首先会发起选举,但是其他的节点会告诉他我们已经有leader了,然后此节点会自动变成follower。
如果集群刚启动或者leader出现了问题,那么集群会进入崩溃恢复模式选举产生新的leader。新的leader出现后,有超过半数的follower已经与leader同步过数据后集群就进入了消息广播模式,即正常工作模式
数据同步
正常的同步
zookeepe使用自己的zab协议实现数据同步。 写请求都会转发到leader上,随后leader会发出一个proposal,leader与follower之间的通信是通过队列来实现的并且每个proposal都有一个唯一的zxid,因此保证了follower中数据写入的顺序。当follower收到proposal后会写入本地日志到磁盘,并返回ack给leader。leader收到大多数的follower的ack后自己commit然后通知各个follower也commit同时返回客户端结果。
重新选举出leader后的同步
新leader先判断自己的未被commit的proposa是否能够commit(依据是此时整个集群额大多数节点都有这个proposal),如果可以就commit,如果不可以就不commit。因此最开始是先搞好leader的数据,之后leader会告诉follower增减数据。
如果leader刚发出proposal就宕机了,follower都没有收到
那么新产生的leader将不知道有这个proposal,也就相当于这个proposal被废掉了,即使之前的leader加入集群,这个proposal也会被新的leader废掉。
如果leader收到大多数的ack,但是还没有commit
收到的这些follower中肯定会有一个是新的leader。在其成为leader后会“领导大家”commit这个proposal